Research
 String Algorithms
String Algorithms
컴퓨터상의 정보들을 가장 자연스럽고 간단하게 표현하는 방법은 문자열(string)을 이용하는 것이다. 문자열 알고리즘(string algorithm)은 문자열로 표현된 데이터를 처리하기 위한 알고리즘으로, 데이터 검색(search), 압축(compression), 정렬(sorting) 알고리즘 등이 있다. 문자열 알고리즘은 알고리즘의 한 갈래로 오랜기간 연구되어 왔으며, 현재도 활발히 연구되고 있는 분야이다. 우리 연구실에선 보다 효율적으로 문자열을 처리하기 위한 알고리즘들을 개발하고 있으며, 일반적인 조건이 아닌 특수한 조건하에서 문자열을 처리하는 다양한 근사 알고리즘(approximate algorithm)을 개발하고 있다.
 Bioinformatics
Bioinformatics생물정보학(bioinformatics)은 생물학적인 데이터를 다루는 학제간 분야이다. 생물정보학은 생물학, 화학, 물리학, 컴퓨터과학, 수학, 통계학 등을 결합하여 생물 데이터를 분자단위에서 분석하고 해석한다. 복잡하고 거대한 데이터를 다루기 위해 컴퓨터 프로그래밍을 방법론의 일부로 사용하고 있으며, 특히 유전체학 분야에서 활발히 연구되고 있다. 대량의 원시 데이터에서 의미있는 정보를 추출하고 분석하기 위해 다양한 컴퓨터 알고리즘을 사용하고 있다.
 Parallel Algorithms
Parallel Algorithms병렬 알고리즘(parallel algorithm)이란, 두 개 이상의 프로세서를 갖는 컴퓨터 모델에서 수행되는 알고리즘을 연구하는 분야이다. 이는 전통적인 순차 알고리즘과 달리, 주어진 시간에 여러개의 연산을 수행할 수 있다. 알고리즘은 병렬화가 쉬운 것 부터 병렬화가 완전히 불가능한 것까지 존재할 수 있으며, 하나의 문제 역시 병렬화가 가능한 알고리즘과 불가능한 알고리즘 중 어떤 것을 채택하는지에 따라 수행 성능의 차이가 발생할 수 있다. 우리 연구실에선 주어진 알고리즘을 분석하여 평행하다 판단되는 단계들을 병렬적으로 처리하여 성능을 개선하는 방법에 대해 연구하고 있다.
 Time Series Aanalysis
Time Series Aanalysis시계열 데이터(time series data)란, 시간 순서대로 발생하는 데이터의 집합을 의미한다. 시계열 분석(time series analysis)이란, 이러한 시계열 데이터를 해석하여 의미있는 결과를 도출하고, 나아가 미래의 데이터를 예측하는 방법을 연구하는 분야이다. 전통적인 통계 분석부터 인공지능을 이용한 분석에 이르기까지, 여러 분야에서 활발히 연구되고 있는 분야이다. 우리 연구실에선 시계열 데이터를 분석하여 의미있는 패턴을 추출하거나, 데이터의 특성을 파악하는 연구를 진행하고 있다.
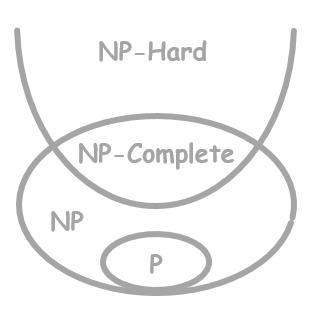 Complexity Theory
Complexity Theory복잡도 이론(complexity theory)이란, 주어진 문제를 해결하는 계산 과정의 자원을 파악하는 계산 이론(computational theory)의 일부로, 컴퓨터 과학에서 핵심이 되는 분야이다. 우리가 해결하고자 하는 문제들은 P, NP, NP-hard 등 여러 클래스로 구분할 수 있으며, 아직 클래스가 밝혀지지 않은 문제도 무수히 존재한다.